Spark SQL
Spark SQL主要用于结构型数据处理,它的前身为Shark,在Spark 1.3.0版本后才成长为正式版,可以彻底摆脱之前Shark必须依赖HIVE的局面。与过去的Shark相比,一方面Spark SQL提供了强大的DataFrame API,另一方面则是利用Catalyst优化器,并充分利用了Scala语言的模式匹配与quasiquotes,为Spark提供了更好的查询性能。
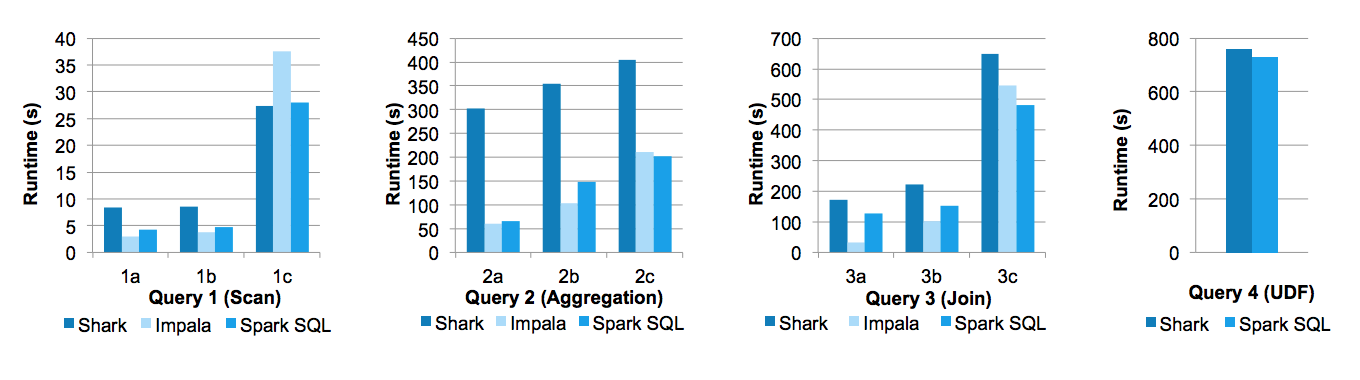
在Databricks工程师撰写的论文《Spark SQL: Relational Data Processing in Spark》中,给出了Spark SQL与Shark以及Impala三者间的性能对比,如下图所示:
Michael Armbrust、Yin Huai等人写的博客《Deep Dive into Spark SQL’s Catalyst Optimizer》简单介绍了Catalyst的优化机制。
就我看来,随着Spark SQL引入DataFrame以及它对多种数据源的支持,在多数大数据分析场景下,Spark SQL会逐渐取代Spark原来基于RDD的编程模式。
Spark SQL利用SchemaRDD为结构型数据的访问提供了统一接口,包括对Hive表、parquet文件、csv文件以及Json文件:
根据DataStax给出的Supported Syntax of Spark SQL,指出了Spark SQL支持的语法:
SELECT [DISTINCT] [column names]|[wildcard]
FROM [kesypace name.]table name
[JOIN clause table name ON join condition]
[WHERE condition]
[GROUP BY column name]
[HAVING conditions]
[ORDER BY column names [ASC | DSC]]
如果使用join进行查询,则支持的语法为:
SELECT statement
FROM statement
[JOIN | INNER JOIN | LEFT JOIN | LEFT SEMI JOIN | LEFT OUTER JOIN | RIGHT JOIN | RIGHT OUTER JOIN | FULL JOIN | FULL OUTER JOIN]
ON join condition