实现PageRank算法
吴军博士在《数学之美》中深入浅出地介绍了由Google的佩奇与布林提出的PageRank算法,这是一种民主表决式网页排名技术。书中提到PageRank的核心思想为:“在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。”同时,该算法还要对来自不同网页的链接区别对待,排名越高的网页,则其权重会更高,即所谓网站贡献的链接权更大。
例如网页Y被X1,X2,X3,X4四个网页所链接,且这四个网页的权重分别为0.001,0.01,0.02,0.04,则网页Y的Rank值=0.01+0.02+0.03+0.04=0.071。但问题是,如何获得X1,X2,X3,X4这些网页的权重呢?答案是权重等于这些网页自身的Rank。然而,这些网页的Rank又是通过链接它的网页的权重计算而来,于是就陷入了“鸡与蛋”的怪圈。解决办法是为所有网页设定一个相同的Rank初始值,然后利用迭代的方式来逐步求解。
在《数学之美》第10章的延伸阅读中,有更详细的算法介绍,有兴趣的同学可以自行翻阅。下面是PageRank的简单执行步骤:
- 首先假定所有网页的初始Rank值为1/N,N为所有网页的数量。
- 开始迭代。每次迭代,则页面p会将r/n的值发送给所有链接了p页面的邻居页面。其中,r为当前页面的rank值,n为链接了当前页面的邻居页面数。该值实则就是当前页面p这次迭代的贡献者(contribution)。
- 每次迭代结束时,都对最终获得的contributions进行求和。假设每个contribution为c(i),则可以通过公式α/N + (1-α)∑c(i)获得每个页面的rank值。其中,α是一个常数值,可以认为是一个调优参数(tuning parameter),N为所有页面的数量。
究竟应该迭代多少次呢?由于PageRank实则是线性代数中的矩阵计算,佩奇和拉里已经证明了这个算法是收敛的。当两次迭代获得结果差异非常小,接近于0时,就可以停止迭代计算。《数学之美》中提到:“一般来讲,只要10次左右的迭代基本上就收敛了。”
我们将初始值进一步简化为1.0,并且将α/N的值设置为0.15,则公式α/N + (1-α)∑c(i)就变成0.15 + 0.85*∑c(i),那么在Spark中的实现为:
val sc = new SparkContext(...)
// 假定邻居页面的List存储为Spark objectFile
val links = sc.objectFile[(String, Seq[String])]("links")
.partitionBy(new HashPartitioner(100))
.persist()
//设置页面的初始rank值为1.0
var ranks = links.mapValues(_ => 1.0)
//迭代10次
for (i <- 0 until 10) {
val contributions = links.join(ranks).flatMap {
case (pageId, (links, rank)) =>
//注意此时的links为模式匹配获得的值,类型为Seq[String],并非前面读取出来的页面List
links.map(dest => (dest, rank / links.size))
}
//简化了的rank计算公式
ranks = contributions.reduceByKey(_ + _).mapValues(0.15 + 0.85 * _)
}
ranks.saveAsTextFile("ranks")
这段代码来自于Learning Spark: Lightning-fast big data analytics一书第4章。它充分地展现了Spark在进行数据分析的优雅与强大。虽然是简化了的PageRank算法,但如此精简的代码量仍然值得称赞。此外,该实现的性能比较Hadoop而言,也有显著提升。在Matei的论文An Architecture for Fast and General Data Processing on Large Clusters中,给出了这样的性能benchmark比较,如下图所示:
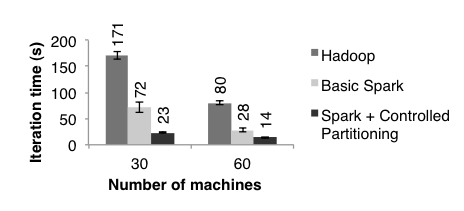
图:Hadoop和Spark关于PageRank算法的性能比较(2014年)
注意,图中比较了Basic Spark与Spark+Controlled Partitioning,后者实则是通过分区等性能调优手段改进算法的性能。在前面的代码段中,我们也看到在读取页面List时,通过了partitionBy()函数传递了一个HashPartitioner。不要小看这段代码,实则它隐藏了许多与性能相关的tips,Learning Spark: Lightning-fast big data analytics一书对此做了深入介绍,性能改进点包括:
- 在迭代中,links每次都与ranks进行了join操作,这是非常影响性能的。由于links的内容是不会变的(static dataset),因此在对它进行分区后,迭代中就不再需要针对它跨网络进行shuffle了。当links的数据量非常大时,这一优化对性能的提升是非常明显的。
- 将分区了的RDD持久化到内存中,这一做法极为关键,理由同前。
- 注意ranks的创建是针对links执行mapValues()而来。ranks需要和links执行join操作。由于mapValues()是一个transform操作,links是ranks的parent RDD,相比join两个完全无关的RDD而言,二者的join操作会更加高效。
- 在迭代中,对contributions执行了reduceByKey()后,紧跟着执行了mapValues()。由于reduceByKey是hash-partition,它又是mapValues的parent RDD,因而mapValues()计算后的RDD即ranks也是hash-partition。而ranks又会在下一个迭代中与前面hash-partition的links进行join操作。join的两个RDD都处于同一分区,效率更高。
此外,对分区后的RDD应尽量调用mapValue()函数,而非map()函数。从Spark对mapValues的实现以及注释可以看到,mapValues()函数会保持原有RDD的分区:
/**
* Pass each value in the key-value pair RDD through a map function without changing the keys;
* this also retains the original RDD's partitioning.
*/
def mapValues[U](f: V => U): RDD[(K, U)] = {
val cleanF = self.context.clean(f)
new MappedValuesRDD(self, cleanF)
}
flatMapValues()与mapValues()相似,也会保持原有RDD的分区,所以为了尽可能地满足与分区有关的性能优化,应合理考虑对RDD操作的选择。