External DataSources
访问JDBC
如果我们要通过JDBC访问关系型数据库,例如PostgreSQL,则可以通过Spark SQL提供的JDBC来访问,前提是需要PostgreSQL的driver。方法是在build.sbt中添加对应版本的driver依赖。例如:
libraryDependencies ++= {
val sparkVersion = "1.3.0"
Seq(
"org.apache.spark" %% "spark-core" % sparkVersion,
"org.apache.spark" %% "spark-sql" % sparkVersion,
"org.postgresql" % "postgresql" % "9.4-1201-jdbc41"
)
}
根据Spark SQL的官方文档,在调用Data Sources API时,可以通过SQLContext加载远程数据库为Data Frame或Spark SQL临时表。加载时,可以传入的参数(属性)包括:url、dbtable、driver、partitionColumn、lowerBound、upperBound与numPartitions。
PostgreSQL Driver的类名为org.postgresql.Driver。由于属性没有user和password,因此要将它们作为url的一部分。假设我们要连接的数据库服务器IP为192.168.1.110,端口为5432,用户名和密码均为test,数据库为demo,要查询的数据表为tab_users,则访问PostgreSQL的代码如下所示:
object PostgreSqlApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("FromPostgreSql").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
val query = "(SELECT * FROM tab_users) as USERS"
val url = "jdbc:postgresql://192.168.1.110:5432/demo?user=test&password=test"
val users = sqlContext.load("jdbc", Map(
"url" -> url,
"driver" -> "org.postgresql.Driver",
"dbtable" -> query
))
users.foreach(println)
}
}
上面的代码将查询语句直接放在query变量中,并传递给SQLContext用以加载。注意在上述的query值中,必须要为执行的sql语句添加别名,如代码中的USERS,否则会抛出异常:
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Every derived table must have its own alias
另一种方式是直接传递表名,然后通过调用registerTempTable()方法来注册临时表,并调用sql()方法执行查询:
object PostgreSqlApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("FromPostgreSql").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
val url = "jdbc:postgresql://192.168.1.110:5432/demo?user=test&password=test"
val dataFrame = sqlContext.load("jdbc", Map(
"url" -> url,
"driver" -> "org.postgresql.Driver",
"dbtable" -> "tab_users"
))
dataFrame.registerTempTable("USERS")
val users = sqlContext.sql("select * from USERS")
users.foreach(println)
}
}
如果查询牵涉到多张表,例如对表进行join,则需要利用SQLContext的load方法分别将这多张表加载到DataFrame中。注意这种load工作其实仅仅是加载了对应表的schema。
如果查询的SQL语句为:
select t1._salory as salory,
t1._name as employeeName,
t2._name as locationName
from mock_employees t1
inner join mock_locations t2
on t1._location_id = t2._id
where t1._salary > t2._max_price
则实现为:
val employeeDF = sqlContext.load("jdbc", Map(
"url" -> url,
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "mock_employees"
))
val locationDF = sqlContext.load("jdbc", Map(
"url" -> url,
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "mock_locations"
))
employeeDF.registerTempTable("Employees")
locationDF.registerTempTable("Locations")
val result = sqlContext.sql(
"""
|select t1._salary as salary,
|t1._name as employeeName,
|t2._name locationName
|from Employees t1
|inner join Locations t2
|on t1._location_id = t2._id
|where t1._salary > t2._max_price
""".stripMargin
)
当然,我们也可以直接将sql语句作为load()方法中dbtable的值传入,实现代码为:
val query =
"""
|(select t1._salary as salary,
|t1._name as employeeName,
|t2._name locationName
|from mock_employees t1
|inner join mock_locations t2
|on t1._location_id = t2._id
|where t1._salary > t2._max_price) as EMP
""".stripMargin
val dataFrame = sqlContext.load("jdbc", Map(
"url" -> url,
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> query
))
可以调用DataFrame的queryExecution来查看执行计划,发现前者的执行计划与后者有天壤之别。第一种方式的queryExecution结果:
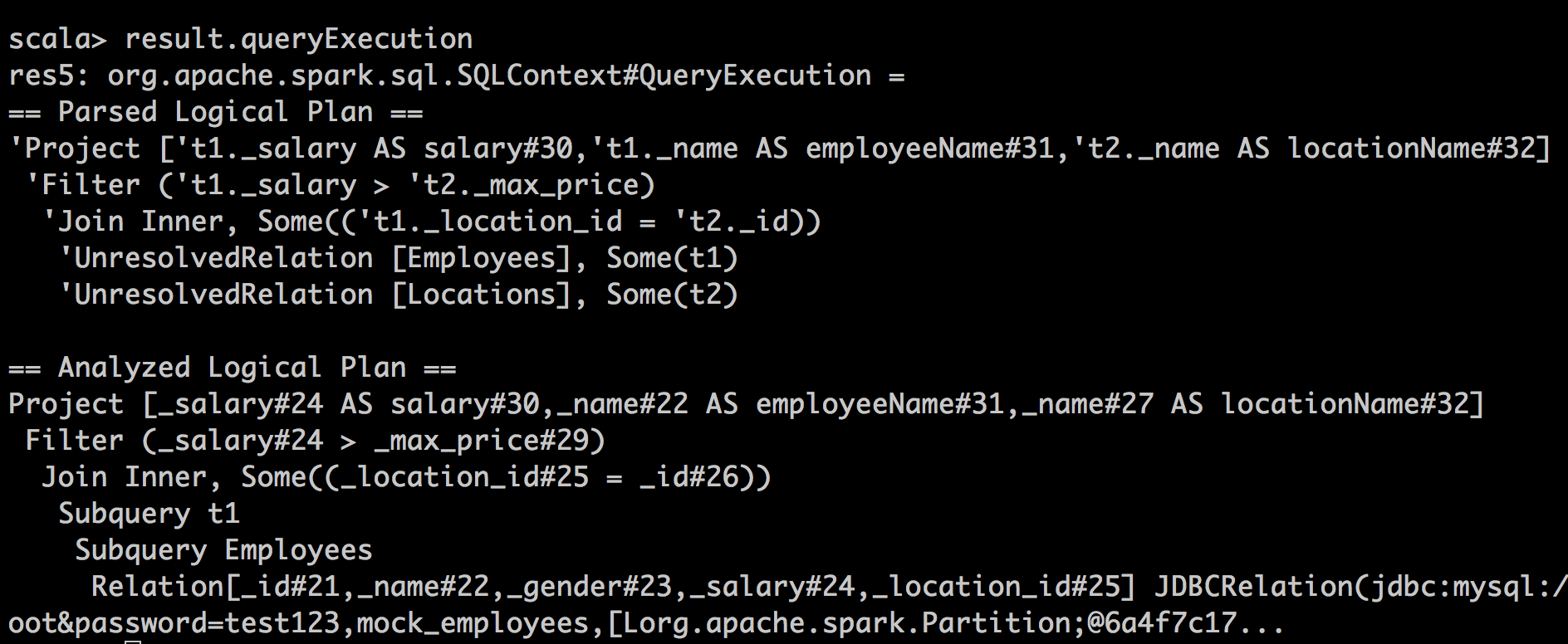
第二种方式的queryExecution结果:
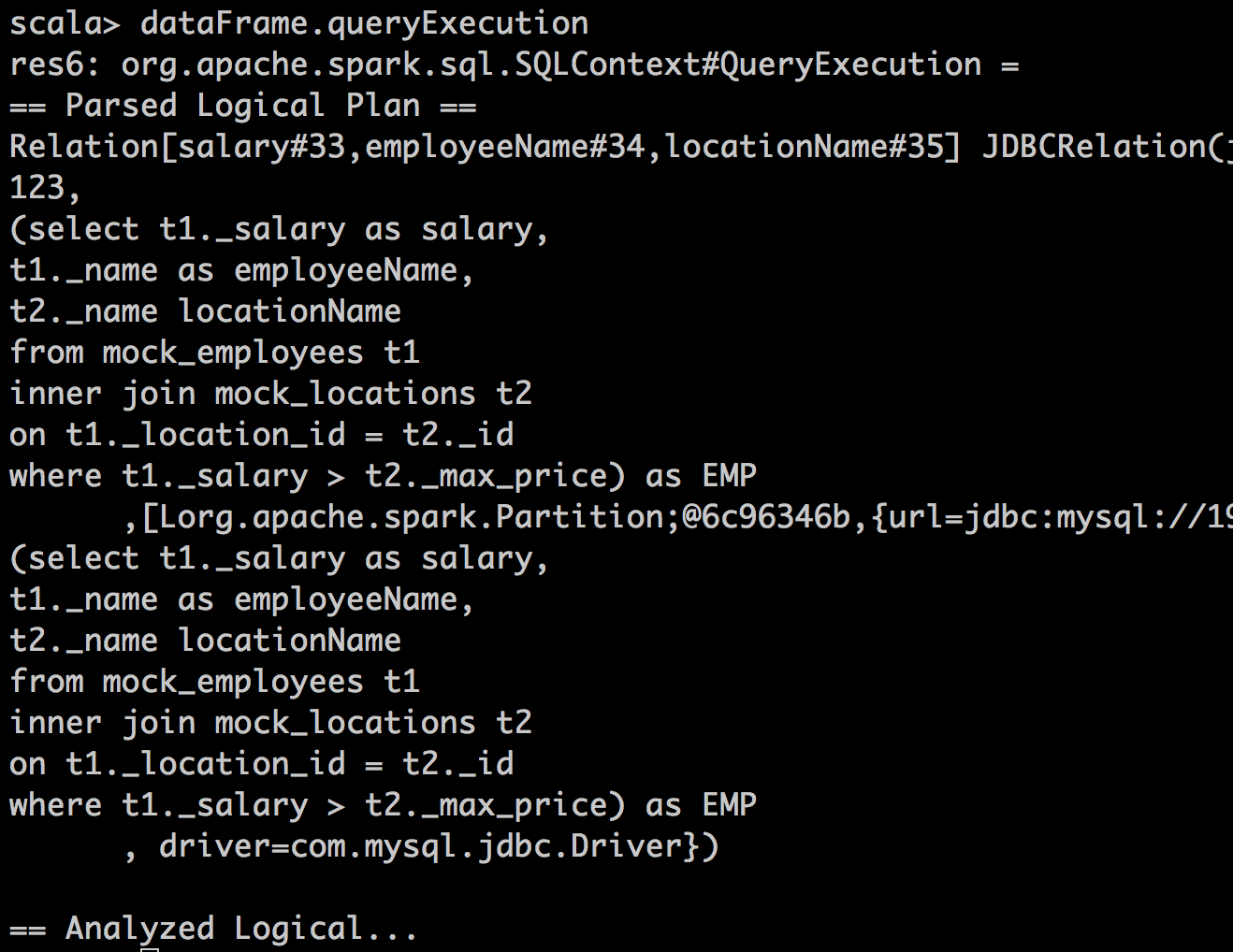
显然,第一种方式运用catalyst对其进行了一定程度的优化,例如建立了filter、join等执行计划,后者则保持了sql语句的原样,本质上讲就成了对JDBC的一个包装,因而无法享受到catalyst优化器带来的福利。
Spark SQL的DataFrame自身提供了可以操作数据的API,也支持使用SQL语法。例如,下面两段代码的运行结果除了count列名稍有不同外,schema与数据完全是一样的:
//使用SQL语法
val emps = sqlContext.sql("SELECT name, count(*) FROM Employees WHERE salary > 4000.0 GROUP BY name")
//使用DataFrame的API
emps.filter(emps("salary") > 4000.0).groupBy("name").count
使用Spark-Shell
Spark提供的shell工具Spark-Shell对于探索样本数据的算法非常有帮助。自从Spark SQL成为正式版本后,启动Spark-Shell后除了实例化了SparkContext之外,还实例化SQLContext,默认名为sqlContext。在Spark Shell中,可以自如地操作sqlContext,利用Spark SQL去访问结构数据,获得DataFrame。
当我们需要通过JDBC访问外部数据库如MySQL、PostgreSQL时,需要将对应的JDBC Driver在启动Spark Shell之前将其放入到classpath中,否则,在Spark-Shell中输入如下语句时,会抛出ClassNotFoundException,提示找不到对应的driver class:
val employeeDF = sqlContext.load("jdbc", Map(
"url" -> url,
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "mock_employees"
))
解决方案是在SPARK_HOME/bin/compute-classpath.sh中将数据库驱动追加到classpath下。我们可以考虑在SPARK_HOME下创建一个libs目录,专门用于存放程序需要的外部依赖jar包。例如,把MySQL的驱动程序jar包拷贝到该目录下,然后在compute-classpath.sh脚本中增加如下配置:
appendToClasspath "$FWDIR/libs/mysql-connector-java-5.1.35.jar"
Spark SQL的优势
对比传统方式访问JDBC/ODBC服务器,Spark SQL可以为多个程序提供缓存功能,从而提升程序的性能。Spark SQL还为SQL语句的执行提供了优化的执行计划。