DataSources
随着Spark SQL的正式发布,以及它对DataFrame的支持,它可能会取代HIVE成为越来越重要的针对结构型数据进行分析的平台。在博客文章What’s new for Spark SQL in Spark 1.3中,Databricks的工程师Michael Armbrust着重介绍了改进了的Data Source API。

我们在对结构型数据进行分析时,总不可避免会遭遇多种数据源的情况。这些数据源包括Json、CSV、Parquet、关系型数据库以及NoSQL数据库。我们自然希望能够以统一的接口来访问这些多姿多态的数据源。
Parquet
Apache Parquet是被主要用于Hadoop生态系统中的列式存储格式,它与数据模型、编程语言以及数据处理框架无关。Parquet在数据压缩、列式数据展现等方面具有非常大的优势。Parquet文件schema的设计灵感来自Dremel的论文。
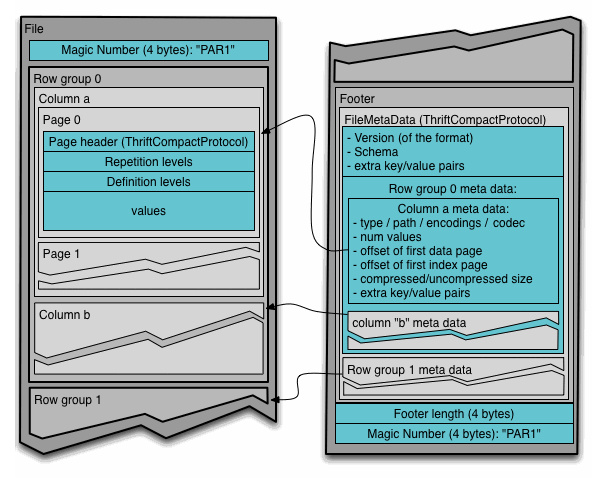
Parquet格式可以简单地分为四个层次,分别为File、Row Group、Column Chunk和Page。一个File通常包含一到多个Row Group。Row Group是一种对数据的逻辑水平分区,从而将数据分为多个行(Row)。一个Row Group包含多个Column Chunk,其中,每个Column Chunk都是针对一个特定列的数据块。一个Column Chunk又被分解为多个Page。为了压缩和编码的方便,Parquet将Page作为最小的不可分割单元。
为了支持对Parquet数据的高效编码,Parquet提供了元数据文件,元数据包含了所有列元数据开始的位置。元数据会在写入数据之后被写入,而在读取Parquet数据时,会首先读取文件的元数据找到所要处理的column chunk。在读取Row Group包含的column chunk时,以顺序方式读取。下图是Parquet官方网站给出的文件格式示意图:
DataFrame提供了saveAsParquetFile()方法,可以将DataFrame的内容写到parquet文件中。例如:
val row1 = Row("Bruce Zhang", "developer", 38 )
val row2 = Row("Zhang Yi", "engineer", 39)
val table = List(row1, row2)
val rows = sc.parallelize(table)
import org.apache.spark.sql.types._
val schema = StructType(Array(StructField("name", StringType, true),StructField("role", StringType, true), StructField("age", IntegerType, true)))
sqlContext.createDataFrame(rows, schema).registerTempTable("employee")
sqlContext.sql("select * from employee").saveAsParquetFile("employee.parquet")
saveAsParquetFile()方法接受的是路径名,可以是本地路径,也可以是HDFS的路径。因而,这里生成的是employee.parquet目录,parquet数据文件和元数据文件皆放在这个目录下: