DataFrame
对于结构型的DataSet,DataFrame提供了更方便更强大的操作运算。事实上,我们可以简单地将DataFrame看做是对RDD的一个封装或者增强,使得Spark能够更好地应对诸如数据表、JSON数据等结构型数据样式(Schema),而不是传统意义上多数语言提供的集合数据结构。在一个数据分析平台中增加对DataFrame的支持,其实也是题中应有之义。诸如R语言、Python的数据分析包pandas都支持对Data Frame数据结构的支持。事实上,Spark DataFrame的设计灵感正是基于R与Pandas。
DataFrame本质上是一个分布式集合,即组合了Row对象的RDD。Row内部的数据结构由一组命名了的列(named columns)组成。如果观察Row的定义,可以看到定义在其中的schema属性,它的类型为StructType。
@Experimental
class DataFrame private[sql](
@transient val sqlContext: SQLContext,
@DeveloperApi @transient val queryExecution: SQLContext#QueryExecution)
extends RDDApi[Row] with Serializable
trait Row extends Serializable {
/**
* Schema for the row.
*/
def schema: StructType = null
}
@DeveloperApi
case class StructType(fields: Array[StructField]) extends DataType with Seq[StructField]
以上代码为Spark 1.3,可以看到DataFrame并没有继承自RDD,而是继承了一个名为RDDApi的trait。该trait提供了与RDD非常相似的Api:
private[sql] trait RDDApi[T] {
def cache(): this.type
def persist(): this.type
def persist(newLevel: StorageLevel): this.type
def unpersist(): this.type
def unpersist(blocking: Boolean): this.type
def map[R: ClassTag](f: T => R): RDD[R]
def flatMap[R: ClassTag](f: T => TraversableOnce[R]): RDD[R]
def mapPartitions[R: ClassTag](f: Iterator[T] => Iterator[R]): RDD[R]
def foreach(f: T => Unit): Unit
def foreachPartition(f: Iterator[T] => Unit): Unit
def take(n: Int): Array[T]
def collect(): Array[T]
def collectAsList(): java.util.List[T]
def count(): Long
def first(): T
def repartition(numPartitions: Int): DataFrame
def coalesce(numPartitions: Int): DataFrame
def distinct: DataFrame
}
为了理解方便,我们可以将DataFrame视为数据库中的一张表。Spark SQL可以将结构型数据文件(Json、Parquet)、Hive表、外部数据源以及现有的RDD创建为一个DataFrame。
例如我们通过外部Json文件创建一个DataFrame:
val dataFrame = sqlContext.load("/example/data.json", "json")
dataFrame.show()
在加载结构数据文件时,默认的类型为Parquet,此时可以在加载时不用指定文件类型:
val dataFrame = sqlContext.load("/example/person.parquet")
当然,你也可以不调用load()方法,而是根据数据源选择对应的方法,例如加载json文件可以调用jsonFile()方法,加载parquet文件,调用parquetFile()方法。
针对数据操作,DataFrame提供了对应的DSL风格的APIs,例如常见的select、filter、groupBy和join()等。例如:
young = users.filter(users.age < 21)
young = users.select(young.name, young.gender)
young.groupBy("gender").count
young.join(logs, logs.userId == users.userId, "left_outer")
当然,为了更好地和关系型数据库操作契合,Spark SQL支持以SQL方式操作数据。这可以通过调用SqlContext的sql()方法来完成。在执行SQL之前,需要讲加载的数据注册为临时表:
val dataFrame = sqlContext.load("example/person.parquet")
dataFrame.registerTempTable("person")
dataFrame.sql("SELECT count(*) FROM person")
注册的临时表为SQLContext所使用,在程序退出后就会消失。
DataFrame提供了和RDD相似的lazy机制,将作用于它之上的操作分为Transform与Action两大类,只有在调用DataFrame的Action操作,才会真正被执行计算。例如,在上述代码中,并没有真正执行select语句,只有当调用诸如show,collect或者save等操作时,才会真正执行。采用这种方式,可以使执行的计算能够被更好地优化。 若从编码角度思考,Spark SQL优势在于两种编程风格可以兼而有之,鱼与熊掌二者兼得,从而使得编码更加自如而赏心悦目。例如,我们可以先通过SQL语句的执行方式获得DataFrame,由于DataFrame本身是一个Monad,我们又可以对其调用map、filter等操作。例如我们可以将每一行数据map为一个tuple:
val firstPerson = dataFrame.sql("SELECT * FROM person)
.map(row => (row.getLong(0), row.getString(1), row.getString(2))
.first()
由于DataFrame中存储的是Row对象,在map时可以根据各个列的类型选择调用Row的getXXX()方法。如果开发语言选择Python,则可以只通过传入下表来获得。Scala和Java的静态语言特性存在一定的限制,虽然在Scala中可以通过调用get(i: Int): Any获得对应列的值,但仍然需要安全的类型转换。
集合转换为DataFrame
我们也可以通过调用parallelize()方法结合集合创建需要分析的数据,并创建数据表的Schema。例如,创建一个具有三列(Field)两行的表:
import org.apache.spark.sql._
import org.apache.spark.sql.types._
val row1 = Row("Bruce Zhang", "developer", 38 )
val row2 = Row("Zhang Yi", "engineer", 39)
val table = List(row1, row2)
val rows = sc.parallelize(table)
val schema = StructType(Array(StructField("name", StringType, true),StructField("role", StringType, true), StructField("age", IntegerType, true)))
sqlContext.createDataFrame(rows, schema).registerTempTable("employees")
sqlContext.sql("SELECT * FROM employees").collectAsList()
Spark SQL UDFs
UDFs即User-Defined Functions,它使得我们可以注册自己编写的函数,用以丰富SQL执行。通过SQLContext可以得到udf来注册函数。在Scala中,它支持正常定义的scala方法、函数或者表达式。例如,针对前面的DataFrame,我们注册一个获取字符串长度的函数。有三种方式:
//方式1:使用表达式
sqlContext.udf.register("lenOfStr", (_:String).length)
//方式2:使用方法
def len(s: String) = s.length
sqlContext.udf.register("lenOfStr", len _)
//方式3:使用函数
val length: String => Int = _.length
sqlContext.udf.register("lenOfStr", length)
sqlContext.sql("SELECT lenOfStr('name') FROM employees LIMIT 10")
join操作
DataFrame之间可以直接进行join。Spark SQL会默认为DataFrame的列命名为_n,其中n的值从1开始。join的关键字就可以利用这个默认的列名(attribute),例如:
val df1 = sqlContext.createDataFrame(Seq((1, "a"), (2, "b"), (3, "b"), (4, "b")))
val df2 = sqlContext.createDataFrame(Seq((1, 10), (2, 20), (3, 30), (4, 40)))
df1.join(df2, df1("_1") === df2("_1")).printSchema
连接后,打印出来的schema如下所示:
root
|-- _1: integer (nullable = false)
|-- _2: string (nullable = true)
|-- _1: integer (nullable = false)
|-- _2: integer (nullable = false)
由于默认的列名都采用了同样的命名规则,在join时都需要指定DataFrame。为了避免列名的混淆,并简化调用,DataFrame还支持别名的形式:
df1.as('a).join(df2.as('b), $"a._1" === $"b._1")
或者为列名重命名:
df1.join(df2.withColumnRenamed("_1", "id"), $"_1" === "id")
从Spark 1.4后,DataFrame增加了一个新的join()方法重载,支持直接传入列名的方式,简化了如上实现方式。新增的join()方法定义为:
def join(right: DataFrame, usingColumn: String): DataFrame
前面的例子就可以简化为:
df1.join(df2, "_1")
缓存
DataFrame通过cache()方法提供了缓存功能,但它并非立即执行的。调用cache()方法后,若第一次执行action操作,此时缓存的执行被触发,但本次执行并没有享受到缓存的福利;只有当执行第二次时,执行的操作才会从缓存中取出,而非再度访问数据源,除非缓存已失效。例如:
val df = sqlContext.sql("select c1, sum(c2) from T1, T2 where T1.key=T2.key group by c1")
df.cache() // 缓存执行后的dataframe,但它是延迟执行
df.registerAsTempTable("my_result")
sqlContext.sql("select * from my_result where c1=1").collect // 第一次查询时,缓存被触发
sqlContext.sql("select * from my_result where c1=1").collect // 直接从缓存中查询
Spark SQL还支持对特定表的缓存:
sqlContext.cacheTable("T1")
sqlContext.cacheTable("T2")
对表进行缓存时,给定的表名必须与注册的表名保持一致。注意表名是大小写敏感的。如果给定错误的表名,则会提示:
java.lang.RuntimeException: Table Not Found: Employees1
at scala.sys.package$.error(package.scala:27)
at org.apache.spark.sql.catalyst.analysis.SimpleCatalog$$anonfun$1.apply(Catalog.scala:111)
at org.apache.spark.sql.catalyst.analysis.SimpleCatalog$$anonfun$1.apply(Catalog.scala:111)
at scala.collection.MapLike$class.getOrElse(MapLike.scala:128)
at scala.collection.AbstractMap.getOrElse(Map.scala:59)
at org.apache.spark.sql.catalyst.analysis.SimpleCatalog.lookupRelation(Catalog.scala:111)
at org.apache.spark.sql.SQLContext.table(SQLContext.scala:945)
at org.apache.spark.sql.CacheManager.cacheTable(CacheManager.scala:51)
at org.apache.spark.sql.SQLContext.cacheTable(SQLContext.scala:215)
... 49 elided
我们可以通过Spark Application UI去查看当前的存储状况。假定我们已经在SQLContext中注册了表Employees,然后对该表进行缓存:
sqlContext.cacheTable("Employees")
查看UI,可以发现存储状况显示为空,说明数据并没有被缓存:

只有当执行了真正触发了任务执行的方法,例如collect()后,才能看到存储信息中有了缓存的信息:

缓存的名称为In-Memory table Employees,同时还可以看到缓存分区、内存容量、磁盘容量等消息。打开该缓存,还能看到更加详细的信息:
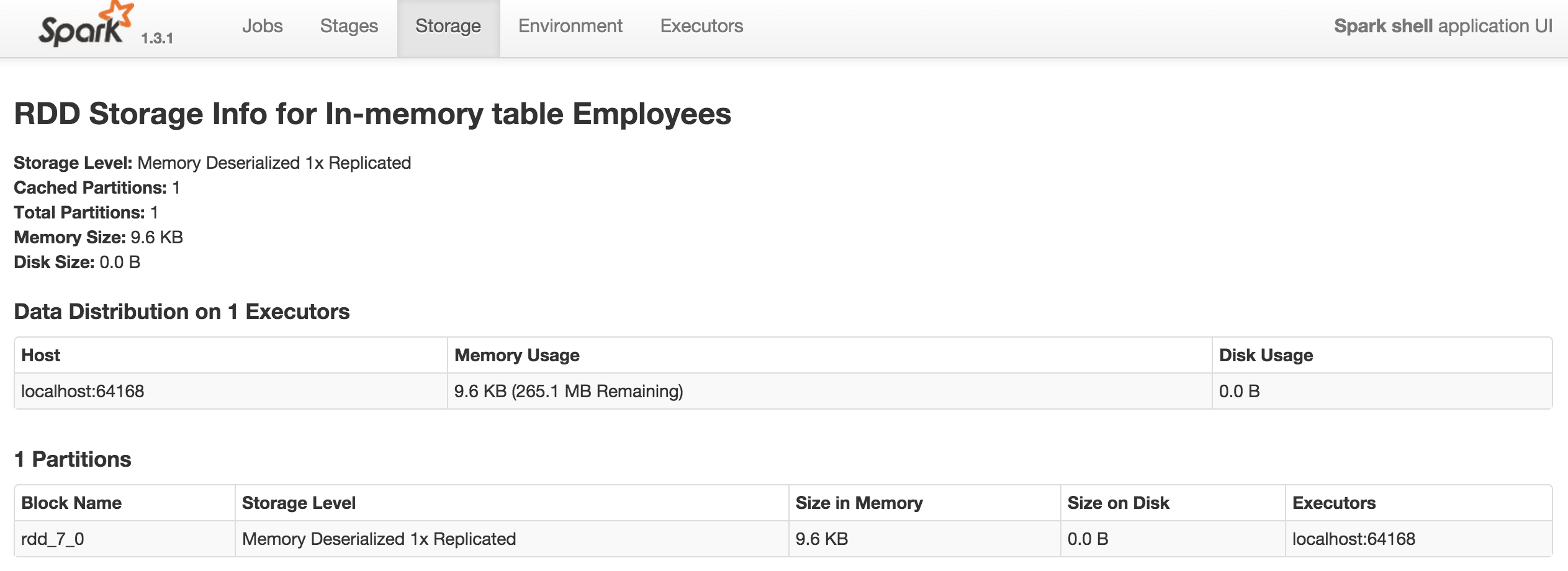
当我们再执行uncacheTable()方法后,则可观察到缓存的内容消失了。
我们很少对一个表的所有列感兴趣,我们可以挑选出需要的列(类似数据清洗)作为一个单独的表进行缓存,从而减小内存的压力,并提升数据处理性能。缓存在内存中的数据仍然保持了DataFrame的数据结构。